
Maps of the Megamachine | Part III | Recommended to Death
Part III of XX | neobehaviourism, cybernetics, cellular automata, looping effects |

Every interaction should be a recommendation.
— Brent Smith & Greg Linden, “Two Decades of Recommender Systems at Amazon.com” (2017)

I. System
Though the cultural roar of the recommendation system (RS) grows more deafening by the hour, the digitalization of decision-making has been underway for a while. First appearing at the tail-end of the 1960s, decision-support systems were a staple of the corporate world long before the advent of Web 1.0.
Designed to automate the administrative burden of management, the software was simple, stepwise and company-specific: a decentralized parochialism that confined the network effects and scaling laws to individual offices and operating systems.
In 1992, a group of engineers from the Xerox Palo Alto Research Centre developed the first collaborative filtering algorithm, christened Tapestry, which allowed Xerox employees to crowdsource the priority or ‘value’ of workplace emails. Procedurally, the collaborative aspect of Tapestry worked by (i) building a database of users and item preferences; (ii) finding the nearest neighbours of users according to said preferences; before (iii) recommending items to bring nearest neighbours nearer still.
In 1994, working out of the MIT Media-Lab, researchers Upendra Shardanand and Pattie Maes applied collaborative filtering to the world of music: an application that would lead to the discovery of a strong correlation between preferences for classical music and The Beatles.1 “It is an epiphany that perhaps makes sense when you think about it for a second,” writes Clive Thompson, “but it isn’t immediately obvious.”2 Though decision-support systems and collaborative filtering algorithms had been growing more connected and complex throughout the 1980s, the year 1996 would give rise to the moment when, to borrow the famous formulation of Philip W. Anderson, more became different.3
In 1996, working out of a Stanford dorm, Larry Page and Sergey Brin introduced the online world to BackRub: a hypermediative computer program, whose system of “spiders” crawled the web for links, before then ranking the results of the search according to scores assigned by an algorithm called PageRank. Though under a different name, Google was born. Visualizing the Internet as spreadsheet, Page and Brin not only formalized the journeys between search and result as optimal or suboptimal routes, but as expressions of value. It was at this inflection point that decision-support systems would find a new designation—recommendation systems—and a new demographic—we, the recommendees.
Web 2.0 was en route.

In 1997, Amazon served 1.5 million customers: an eightfold increase on the previous year.4 Despite being an early adopter of collaborative filtering, however, the influx of new (neighbourless) users quickly disrupted the flow of book recommendation. As Badrul Sarwar and his colleagues describe, Amazon had run into a data sparsity or cold-start problem:
The largest E-commerce sites operate at a scale that stresses the direct implementation of collaborative filtering. In neighbourhood-based CF systems, the neighbourhood formation process, especially the user- user similarity computation step turns out to be the performance bottleneck, which in turn can make the whole process unsuitable for real-time recommendation generation.5
By the tail-end of 1997, however, the newly-hired Greg Linden had engineered a way around the bottleneck of preference elicitation: a workaround that, according to Amazon lore, would lead to Jeff Bezos kneeling in Linden’s office, chanting the phrase “I am not worthy, I am not worthy.”6 Amazon would launch item-to-item collaborative filtering the following year: an approach to recommendation that swapped out user-user for item-item similarity. As Derek Thompson explains:
The key to this formula, which goes by the term ‘item-to-item collaborative filtering,’ is that it’s fast, it’s scalable, it doesn’t need to know much about you.7
A transferable business asset. Those are the words one will find within the “Privacy Notice” on Amazon.com, which every transferable business asset signs.8
By dethroning ‘the user’ as the fundamental unit of analysis, the item-centric algorithm could navigate the great unknowns of empty databases, producing hyper-efficient recommendations based on as few as two or three items. Yet, returning to the credo of Philip W. Anderson, strange things happen at scale. For despite being at the .vanguard of recommendation, Pattie Maes was one of the earliest to forewarn about the antisocial and narrow-minded potentials of decision-support, citing word of mouth as a possible “lost externality” of the future.9
Indeed, along these lines, AI researchers Chiara Longoni and Luca Cian have documented the emergence of a phenomenon known as the “word of machine” effect, which the pair define as “the circumstances in which people prefer AI recommenders to human ones.”10 In terms of a Gaussian distribution, Longoni and Cian found that while human recommendations dominated the tails—greater in extrema—machine recommendations dominated the median—greater on average.
Thus, despite the fact that our human researchers recommend “augmented intelligence” as the road to perfect recommendation—see the loop?—it is not difficult to envisage a number of possible worlds, as Maes did, where a culture of satisficing takes hold,11 scaling asymmetries lead recommendation down paths of least resistance and greatest dependence, and the decibel level of “word of mouth” approaches zero.
II. Micro
At a microscopic level, the neobehavioural capabilities of recommendation are reconstituting human agency from the bottom-up. In “There’s Plenty of Room at the Bottom,” a famous lecture delivered to the American Physics Society in 1959, Richard Feynman set the stage for the bottom-up revolution:
It is a staggeringly small world that is below. In the year 2000, when they look back at this age, they will wonder why it was not until the year 1960 that anybody began seriously to move in this direction.12
Since 1998, Amazon has been moving in this direction at scales and speeds hitherto unseen, for while user-user collaborative filtering required the presorting and rank-ordering of users, items and preferences, item-item collaborative filtering requires no such triage. Inside the algorithmic architecture of Amazon, as Jeff Bezos was known to say, “good intentions don’t work; but mechanisms do.”13
Atom by atom, we’ll assemble tiny machines that will enter cell walls and make repairs. This month comes the extraordinary but also inevitable news that we’ve synthesized life. In the coming years we’ll not only synthesize it, but we’ll also engineer it to specifications. I believe you’ll even see us understand the human brain. Jules Verne, Mark Twain, Galileo, Newton.
— Jeff Bezos, “A Crucial Moment at Princeton” (2010)
For Amazon, the itemization of the bionic and biotic inputs of recommendation has become central to operations. As recounted by Brian McBridge, Amazon UK Managing Director:
Jeff would never dream of changing a pixel, a button, a place on the checkout, or anything on the website, unless you articulated to Jeff what it was going to do to the customer.14
Users are worth less than the sum of their parts, for the product is not the user per se, but the vector space of user behaviour per datum. Indeed, as Scott Galloway has noted, the very decision to begin with books was not born of some holistic love of literature, but of an atomistic passion for logistics: “Easy to recognize, kill, and digest. Books stacked in a warehouse.”
In 2018, Reuters reported that Amazon engineers had, starting in 2014, been developing a machine-learning tool to sift through online résumés and rank possible job candidates from one to five stars—just like Amazon products themselves.
— Brian Christian, The Alignment Problem (2020)
Amazon uses complex algorithms to track the productivity of its warehouse workers, and can reportedly even automatically generate the paperwork required to fire underperformers.
— Colin Lecher, “How Amazon Automatically Tracks and Fires Warehouse Workers for ‘Productivity’” (2019)
In this sense, the rise of Amazon has coincided rather fortuitously the emerging field of Big Behavioural Data (BBD), whose breakthrough technologies are breathing new life into such disciplines as ethology (the study of animal behaviour) and neobehaviourism (an offshoot of behavioural psychology, which seeks to close the gap between behaviourism and cognitivism).
Once these high-level expectations are established, each group begins work on its own more granular operating plan—known as OP1—which sets out the individual group’s ‘bottom-up’ proposal.15
Though one would be forgiven for presuming the above quotation was pulled from the manual of some neobehavioural research team, those are the words of Colin Bryar and Bill Carr, Amazon alumni, whose book Working Backwards lays out the structure of the company in glowing terms.
Throughout history, scientists have struggled to find the fundamental building blocks of human nature: within the domain of behaviourism, S-R (stimulus-response) still holds sway, ethologists have broken down movement into ‘movemes’ (the behavioural equivalent of ‘phonemes’ in language), cyberneticists have postulated the existence of a singular ‘cognitive tile,’ whilst a variety of ‘social atoms’ and ‘social molecules’ have emerged from the field of macrosociology.
Historically, the study of decision-making has been circumscribed by the constrictive laboratory conditions: volunteers pressed A/B buttons, rodents moved through T-mazes, et cetera. Even with such constraints in place, however, the postural and phasic measurement of long, high frame-rate videos (each of which had to be annotated by hand) was a Sisyphean task. There was plenty of room at the bottom, but no way of getting there.
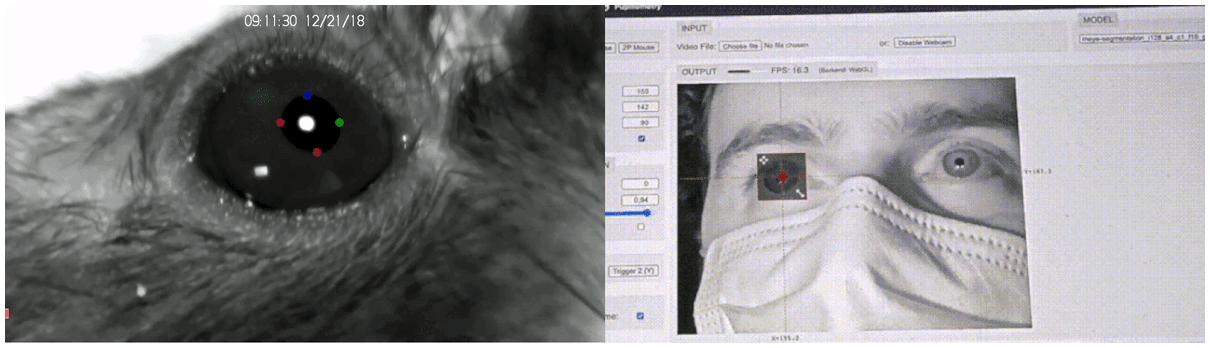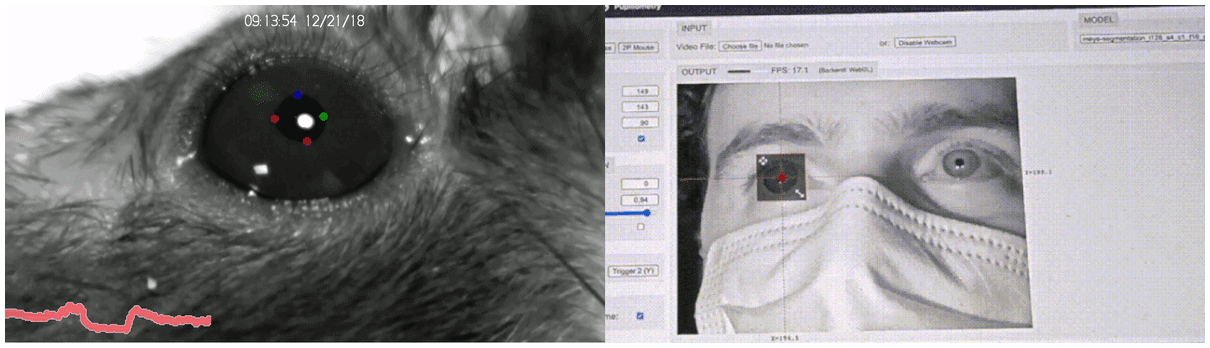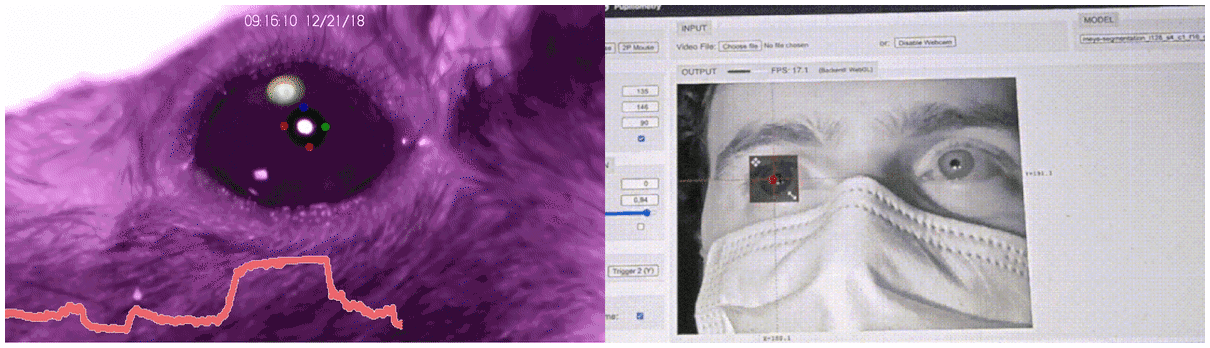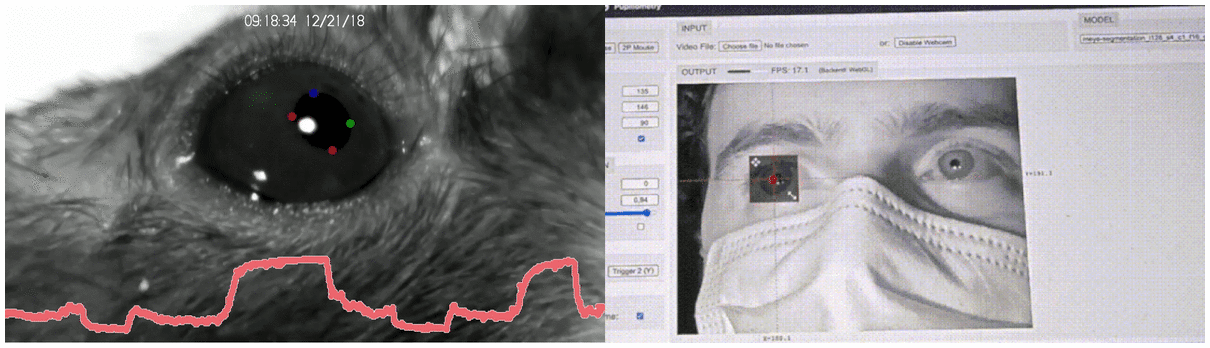
In the wake of BBD, however, as Alex Marin-Gomez and his colleagues reveal, granularity has reached an all-time low:
A ballpark estimate of the dimensionality of the raw data from a ‘manual’ ethogram by a human observer at say 100 bit per s when contrasted with a reasonable video recording yields an astonishing 10,000,000-fold increase in the data rate.16
On the subject of ballparks, Amazon was amongst the first companies to take BBD technologies to market, partnering with the MLB (Major League Baseball) almost a decade ago. Bootstrapping a ballistic missile defence system to process 4K streaming in real time, Amazon Kinesis offered the MLB upwards of 7TB of “raw statistical data” per game—an output that would begin “shedding quantitative light on age-old, but never verified, baseball pearls of wisdom like ‘never slide into first.’”17
Such real-world dataism is not exclusive to Kinesis, but rather constituent of “being Amazonian,”18 an infrastructuralized ethic of rigid utilitarianism, which values the micromanagement of “controllable input metrics”19 above the judgement of even the highest-ranking humans at Amazon.
Amazon can get small changes done much faster, as decision-making is pushed downward as far as it can go.
— Justin Bariso, “Life at Google Versus Life at Amazon” (2021)
In tandem with the launch of Amazon Go (a chain of cashierless supermarkets) and the acquisition of Whole Foods (20,000,000 ft2 of supermarket floor), the Everything Store has unveiled Amazon One: a “payment” technology, which verifies users by scanning “the minute characteristics of your palms—both surface-area details like lines and ridges, as well as subcutaneous features such as vein patterns.”20
For longstanding Amazon users, however, the confluence of datafication and disembodiment is nothing new. Over the years, Amazon shoppers have posted numerous screenshots of data requests that came with folders full of .zip files containing “cryptic strings of numbers like ‘26,444,740,832,600,000’ for various search queries.”21 while Kindle users have discovered that Amazon not only keeps track of the books one reads, but when one reads them, what definitions one looks up, how long one spends per page, the list goes on.22
Requesting your data from Amazon is an exhausting procession that feels a little bit like a text adventure game designed by Franz Kafka.
Nikita Mazurov, “I Want You Back: Getting My Personal Data from Amazon Was Weeks of Confusion and Tedium” (2022)
In “The Looping Effects of Human Kinds,” Ian Hacking asks a question of the discrete and continuous conceptions of the human condition, cutting to the core of the dataism debate: “Graceless philosophers repeat Plato’s words out of context and talk of carving nature at her joints. Does nature have ultimate joints?”23 It is an age-old question upon which new-age technology has begun to shine laboratized light.

As neuroethologist Germán Sumbre and his colleagues have discovered, for instance, despite being one of the rare species whose limbs allow for near-infinite degrees of freedom, octopuses appear to “create” joints when reaching for objects, potentially as a way of simplifying the otherwise high-dimensionality of the act.24
Perhaps it is true, then, as William Wundt contended, that statistical realities follow psychological laws. Perhaps it is false, as Jeff Bezos waxed agnostic, that one should never slide into first. Perhaps it is irrelevant, for as good mechanisms subsume good intentions, causation disappears; correlation becomes “good enough.”25
One wonders whether the statistical astroturfing of bottom-up causation will reveal the answers or, as Heinz von Foerster feared, destroy the questions.26 Indeed, as a user, one can only wonder, for within Amazon, a sociotechnical system of Daedalian depths, the fundamental building blocks of behaviour are Gödelian in their incompleteness: refined within “black boxes”27 and refracted through “multisided markets.”28
We are compelled to plunge into the mathematics of the quantum theory at the small end, of relativity at the big end.
J. B. S. Haldane, “On Scales” (1930)
III. Macro
At a macro level, meanwhile, the hypercognitive capacities of recommendation are reconstituting human agency from the top-down. Twenty years ago, drawing on two decades worth of iterative computations, Stephen Wolfram published A New Kind of Science, which laid out the principles of cellular automata (CA). A discrete model of computation, CA consists of a grid (analogous to a network) and cells (analogous to nodes), demonstrative of how extremely simple systems can produce extremely complex behaviour. Originally, CA was devised by John von Neumann and Stanislaw Ulam as a possible idealization of biological networks. In the wild, however, as numerous historians and systems theorists have documented, conditions are rarely so cellular.29

In the 1950s, modelling the dynamics of traffic flow by hand, Thomas Schelling pioneered the use of CA in the study of macrosociological phenomena. Like ethology, however, the field of macrosociology was kept beneath the low ceiling of manual computation—that was, until the advent of BBD.
As evidenced by the likes of Duncan J. Watts and Dirk Helbing, however, computational social science has begun to effectively factorize the traditional problems of local and and tacit knowledge, as scrutinized by Friedrich Hayek and Michael Polanyi.3031 Coupled with the flattening or “curve fitting” of personal complexes and social contexts into noiseless data (≈ cells), the symbiotic rise of ML and AI (≈ grids) has broken through the ceiling and floor of the “statistical model.”32
In a 1985 interview with MIT’s The Tech, Joseph Weizenbaum famously described computation as a solution looking for a problem.33 Since the turn of the century, echoing Weizenbaum, recommendation—a matrix factorization problem, at heart—has emerged as a sociotechnical locus of solutionism.34
In essence, matrix factorizations resemble a more dimensional or “multilayer” class of CA models, whose columns and rows are scattered with items, itemized behaviours and itemizable correlations. Thus, recommendation is conducive to Bayesian analysis: a method of statistical inference, which uses prior probabilities to assign weighted likelihoods to possible worlds. In the opening pages of Superintelligence, Nick Bostrom conceptualizes Bayesian probability as mounds of sand on a vast sheet of paper:
Imagine also a layer of sand of even thickness spread across the entire sheet: this is our prior probability distribution. Whenever an observation is made that rules out some possible worlds, we remove the sand from the corresponding areas of the paper and redistribute it evenly over the areas that remain in play.35
The virtue of the above metaphor not only rests in its descriptiveness, but its inclusion of depth. In the tailwinds of ML and AI, the computational capacity of recommendation has grown to be able to factorize multiple matrices simultaneously, one layered upon the other—a technique known as deep learning. Architecturally, recommendation has become a stack: a “multidimensional vector space,”36 wherein correlations are not only calculated laterally, but vertically, diagonally, nonlocally. It is less an outdating than an updating of Thomas Schelling’s Micromotives and Macrobehaviour, for while the original formulation still stands, recommendation has opened a parallel pathway between microbehaviour and macromotives.
For every conceivable thought, a network could be devised that connects to it and is thus able to think, whereby the mind or ‘spirit’ (‘Geist’) suddenly finds itself on the engineer’s desk.
Claus Pias, “The Age of Cybernetics” (2016)
Once Amazon open-sourced item-to-item collaborative filtering in 2003, one the earliest adopters was Netflix: a longstanding client of AWS, which would eventually fully migrate to the cloud computing platform. In terms of the flow of data, whether extractive or applicative, Netflix and Amazon Prime Video are one and the same. On the homepages of both streaming platforms, users are presented with a low-resolution representation of the recommendation stack: columns and rows of suggested titles, which do not betray the complexity of the underlying systems at play.
Whereas Top Picks (TP) and Because You Watched (BYW) rows are the product of Top-N algorithms, operating along depersonalized item-item similarity matrices, “Suspenseful Movies” and other genre-centric rows are the result of Personalized Video Recommendations (PVR) algorithms, which not only incorporate explicit feedback, such as viewing histories, but implicit feedback, such as browsing behaviour.37
We know what you played, searched for, or rated, as well as the time, date, and device. We even track user interactions such as browsing or scrolling behavior.
— Xavier Amatriain, ex-Engineering Director at Netflix38
…the implicit signal is stronger.
Mohammad Sabah, ex-Principal Data Scientist at Netflix39
As journalist Alexis C. Madrigal has documented, genres such as “Suspenseful Movies” are merely surface representations of a deeper database; one that has constructed hundreds of thousands of “altgenres” from the “microtagging” viewing habits, whose titles range from “Feel-Good Foreign Comedies” to “Mother-Son Movies from the 1970s.”40
“We’re gonna tag how much romance is in a movie. We’re not gonna tell you how much romance is in it, but we’re gonna recommend it,” explains Todd Yellin, Netflix’s VP of Product Innovation. “These ghosts in the machine are always going to be a by-product of the complexity. And sometimes we call it a bug and sometimes we call it a feature.”41
In the digital e-clipse of the AWS cloud, the personal and cultural evolution of taste and genre are being reorganized along probabilistic and, therefore, predictable lines of sight.
Individual human beings and even whole nations think little about the fact, since while each pursues its own aim in its own way and one often contrary to the other, they are proceeding unnoticed, as by a guiding thread, according to an aim of nature, which is unknown to them, and are labouring at its promotion.
— Immanuel Kant, “Idea for a Universal History with a Cosmopolitan Aim” (1784)
IV. Meso
At a meso level, the noncorporeal tendencies of RS are redistributing human agency from the middle-out. Joshua Nichols has written about subjects without substance; Katherine Behar, about personalities without people; Slavoj Žižek, about organs without bodies. Increasingly, wherever Big Data is concerned (or concerns itself), the gestalt of ‘the user’ is becoming an all-too-human unit of measurement.
In terms of the levels of analysis, the ultimate (‘why’ questions) is giving way to the proximate (‘how’ questions): a collapsing of narrative causality under the weight of statistical correlation.
The advent of ‘data behaviourism’ (which is also a radical return to positivism), appears as a revenge of the plane of immanence, the advent of a body without organs where the role of the body is eclipsed or taken over by data, closing the digital upon itself through a recursive loop, and eroding the very idea of a situated point of view or perspective on the world.
Antoinette Rouvroy, “Data Without (Any)Body? Algorithmic Governmentality as Hyper-Disadjointment and the Role of Law as Technical Organ” (2014)
Within Amazon, by casting oneself as the agentic protagonist—from the Greek proto- (‘first’) and agonistes (‘actor’)—one risks falling victim to the narrative fallacy: a phrase first popularized by Nassim Nicholas Taleb in The Black Swan, required reading for every Amazon executive.42 In short, the narrative fallacy describes the human tendency to translate complex realities into simplex stories, whose overfitted causal chains serve to hide the true randomness of nature—or, in the case of Amazon, the pseudorandomness of a closed system.
Etymologically, the ‘Kindle’ hearkens back to the myth of Prometheus. As journalist Roisin Kiberd has written, however, Big Data has set the stage for a Prometheus-in-reverse, where the gods steal fire from mankind.43 With Kindle, Amazon has infrastructuralized a looping effect, wherein the tradition of reading as a solitary and secretive act—a way “to release the private, unsocialized dreaming self”44— becomes locked within the self-fulfilling (or self-defeating) prophecies of “controlled consumption.”45 As de facto extensions of the Amazon operating system, Ted Striphas writes, “Kindle users come to comprise a massively distributed ‘artificial artificial intelligence’ whose purpose is to map an ever-evolving ‘ambient informatics’ of reading.”46
If Kindle is upgraded with face recognition and biometric sensors, it can know what made you laugh, what made you sad and what made you angry. Soon, books will read you while you are reading them. And whereas you quickly forget most of what you read, Amazon will never forget a thing. Such data will enable Amazon to evaluate the suitability of a book much better than ever before. It will also enable Amazon to know exactly who you are, and how to turn you on and off.
— Yuval Noah Harari, Homo Deus (2017)
Within such a choice architecture, hyper-agentic by design, the normative horizon of agency extends to such a degree that human agents become hypo-agentic by default.
Hence, the erosion of ‘surveillance’ and ‘privacy’ as concepts of explanatory power, for as users are systemically fractionated across speculative matrices of standardized itemizations, the ‘I’ in question becomes difficult to disentangle.
Predictive models do pinpoint people and do produce personalization. But now the metrics themselves are becoming stand-in political subjects. Unmoored from the individuals they once defined, personality types are gaining autonomous agency.
Katherine Behar, “Personalities Without People” (2018)
Only by reverse engineering can one find oneself; a project that can only transpire on Amazon’s turf, with Amazon’s tools. In an extension of Ian Hacking’s famous phrase, recommendation is not only “making people up,” but making them up and down.

In 1882, Oliver Wendell Holmes, Jr. wrote that “even a dog distinguishes between being stumbled over and being kicked.” As a rule, advancing as a service-oriented architecture that has cemented a reputation for seeing like an algorithm,47 Amazon makes few such distinctions.
Taste, opinion, wishful thinking: within Amazon, the contents of consciousness rarely rise to the level of Gregory Bateson’s definition of information: a difference which makes a difference.48
It’s hard to believe that you could get humans to override all of their values that they came in with… But with a system like this, you can. I found that a bit terrifying.
— ex-Product Manager at Facebook (2021)49
In this sense, the algorithmic architecture of Amazon marks a return to the first-wave cybernetics of Norbert Wiener and Arturo Rosenblueth, whose pared-back connectionism sparked a famous reply from fellow cyberneticist Richard Taylor:
How could Wiener and Rosenblueth base a notion of purposefulness on observable behavior alone, ignoring the blatant distinction between the various intentions behind the observation that a car is following a man? Is the driver trying to run the man down? Making a joke? Trying to frighten him? Or simply veering to rid his car of a pesky bee?50
At Amazon, returning the field of neobehaviourism, the confinement of the (data-)scientific method to the linking of ‘observables’ maps onto the operant model of human behaviour. Operationalizing the “action profiles” of agents,51 human and otherwise, Amazon has architecturalized and codified a “bias for action.”52 In terms of means and ends, particularly over extended periods of extensive use, RS tend toward S-R: the more Amazon algorithms tailor the top-N results with previously-purchased and well-known products,53 the more users value the recommendations and trust the system.54
Studying the neobehavioural turn, Katherine Behar has argued that descriptive demographics are giving way to predictive psychometrics.55 While descriptive demographics are certainly becoming a relic of the past, however, the framework of psychometry fails to account for the macro-micro interoperability of recommendation; particularly, within a sociotechnical system as mechanically mindless as item-to-item collaborative filtering.
When you receive an invitation from someone to connect, you imagine that person making a conscious choice to invite you, when in reality, they likely unconsciously responded to LinkedIn’s list of suggested contacts. In other words, LinkedIn turns your unconscious impulses (to ‘add’ a person) into new social obligations that millions of people feel obligated to repay.
— Tristan Harris, “How Technology Hijacks People's Minds: From a Magician and Google's Design Ethicist” (2016)
It is a perpetuum mobile of operant conditioning, which no longer revolves around a specific operant or operator, but within an operating system. “Big Data promises to eliminate the human ‘middleman’ at some point in the process,” write Danielle Keats Citron and Frank Pasquale.56 Inside Amazon, the point is a vanishing one; no middleman, -woman or -child is safe.
V. Ecosystem
Since the turn of the twenty-fist century, recommendation has a become a feature of the environment: an intersubjective and interobjective phenomenon, like word of mouth or theory of mind, subtly torqueing Homo sapiens at the levels of self and species.
In 2013, Brad Stone published a book entitled The Everything Store. In 2015, Tim Mullaney published an MIT Technology Review article entitled “Everything Is a Recommendation.” In the decade or so since, as Amazon has continued to unbox itself—an unboxing accelerated by the pandemic57—the vertical integration of choice and its architecture is fast-becoming a hypernormalized aspect of ubiquitous computing. ‘Everything’ is increasingly within reach.
There will be a transition into a new and fourth form of material organization—after the mineral, plant, and animal kingdoms will come a kingdom in which the human, though admittedly playing a significant role in this transition, will perhaps only be participating in a phenomenon whose implications and consequences transcend him.
— Pierre Bertaux, Maschine, Denkmaschine, Staatsmaschine (1963)
Research reports have estimated that recommendations account for up to 35 percent of Amazon purchases.58 Even placing the data mining and warehousing to one side, for a company netting sales of close to half a trillion dollars, RS has grown to become a $160-billion piece of infrastructure per annum (for perspective, more than the GDP of Croatia and Luxembourg combined).
Since 2003, moreover, when Amazon published the algorithm in IEEE Internet Computing, the likes of Netflix and YouTube have taken and run with the very same code. Two decades later, Amazon’s algorithm account for 60 percent of YouTube views and 80 percent of Netflix streams.59 The open-sourcing of item-to-item collaborative filtering was not some spur-of-the-moment act of charity, however, but rather a part of more longterm strategy: namely, the infrastructuralization of AWS.
Today, Netflix aside, AWS warehouses the data of Disney, Spotify, Instagram, Reddit, Baidu, Slack, Airbnb, Yelp, Kellogg’s, McDonald’s, General Electric, Johnson & Johnson, Pfizer, NASA, NASDAQ, Harvard Medical School, the US Food and Drug Administration, the US Department of State, the UK Ministry of Justice, the list goes on. 60
We will have no liability to you for any unauthorized access or use, corruption, deletion, destruction or loss of Your Content or Applications.
— AWS Customer Agreement (2009)61
Sales aside, the “Amazon consumer pulse”62 has come to palpitate from a decisional database of unprecedented scale and scope—a pulse, moreover, with diastolic and systolic governability. During the early months of the Covid-19 pandemic, the world caught a glimpse of the ability of the megamachine to taketh away when, overnight, Amazon removed each and every recommendation widget from it interface, so as to steer customers away from “nonessential” items—to make mindful the normally mindless.63
In 1984, sociologists Trevor J. Pinch and Wiebe E. Bijker published a paper detailing the extension of “the social” into the arena of the hard sciences.64 In the decades since, the hard sciences have repaid the visit many times over: a megamechanization of society, which has led to what N. Katherine Hayles has described as perhaps the most consequential development of the twenty-first century, “the movement of computation out of the box and into the environment.”65 It is a movement that has laid the foundations, not only for the Internet of Things (IoT) and the Internet of Bodies (IoB), but for the Internet of Recommendations (IoR) to close the gap between them.
To paraphrase Winston Churchill, we’re nowhere near the beginning of the end of recommendation engines innovation. It might fairly be observed, however, that we are at the end of the beginning.
— Michael Schrange, “The Transformational Power of Recommendation” (2020)
Be a hero…
Be a god…

References
Upendra Shardanand & Pattie Maes, “Social Information Filtering: Algorithms for Automating ‘Word of Mouth,’” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, eds. Irvin R. Katz, Robert Mack, Linn Marks, Mary Beth Rosson & Jakob Nielsen (Denver: ACM Press, 1995).
Clive Thompson, “If You Liked This, You’re Sure to Love That,” The New York Times, 21 November 2008. https://www.nytimes.com/2008/11/23/magazine/23Netflix-t.html.
Philip W. Anderson, “More Is Different,” Science, Vol. 177, No. 4047 (1972).
Jeff Bezos, “It’s All About the Long Term” in Invent and Wander (Boston: Harvard Business Press, 2020), 31.
Badrul Sarwar, George Karypis, Joseph Konstan & John Riedl, “Item-Based Collaborative Filtering Recommendation Algorithms” in Proceedings of the 10th International Conference on World Wide Web, eds. Vincent Y. Shen, Nobuo Saito, Michael R. Lyu & Mary Ellen Zurko (New York: Association for Computing Machinery, 2001), 289.
Richard L. Brandt, One Click (New York: Portfolio, 2011), 169.
Derek Thompson, “The Algorithm Economy: Inside the Formulas of Facebook and Amazon,” The Atlantic, 12 March 2014. https://www.theatlantic.com/business/archive/2014/03/the-algorithmeconomy-inside-the-formulas-of-facebook-and-amazon/284358/.
Albert Bandura, “Growing Primacy of Human Agency in Adaptation and Change in the Electronic Era,” European Psychologist, Vol. 7, No. 2 (2002).
Pattie Maes: quoted in Kartik Hosanagar, Daniel Fleder, Dokyun Lee & Andreas Buja, “Will the Global Village Fracture Into Tribes? Recommender Systems and Their Effects on Consumer Fragmentation,” Management Science, Vol. 60, No. 4 (2014), 807.
Chiara Longoni & Luca Cian, “When Do We Trust AI’s Recommendations More Than People’s?” Harvard Business Review, 14 October 2020. https://hbr.org/2020/10/when-do-we-trust-ais-recommendations-more-than-peoples.
Herbert A. Simon, Models of Man: Social and Rational (Chichester: Wiley, 1957).
Richard Feynman, “There’s Plenty of Room at the Bottom,” in Engineering and Science (California: California Institute of Technology, 1960).
Jeff Bezos: quoted in Brad Stone, Amazon Unbound (New York: Simon and Schuster, 2021), 100.
Natalie Berg & Miya Knights, Amazon (Kogan Page: London, 2021), 10.
Colin Bryar & Bill Carr, Working Backwards (London: Pan Macmillan, 2021), 18.
Alex Gomez-Marin, Joseph J. Paton, Adam R. Kampff, Rui M. Costa & Zachary F. Mainen, “Big Behavioral Data: Psychology, Ethology and the Foundations of Neuroscience,” Nature Neuroscience, Vol. 17, No. 11 (2014), 1457.
Jeff Bezos, “Big Winners Pay for Many Experiments” in Invent and Wander (Boston: Harvard Business Press, 2020), 140.
Bryar & Carr, Working Backwards, 3.
Ibid., 122.
James Vincent, “Amazon’s Palm Reading Starts at the Grocery Store, but It Could Be So Much Bigger,” The Verge, 1 October 2020. https://www.theverge.com/2020/10/1/21496673/amazon-one-palm-reading-vein-recognition-payments-identity-verification.
Nikita Mazurov, “I Want You Back: Getting My Personal Data from Amazon Was Weeks of Confusion and Tedium,” The Intercept, 27 March 2022. https://theintercept.com/2022/03/27/amazon-personal-data-requestdark-pattern.
Chaim Gartenberg, “Why Amazon Is Tracking Every Time you Tap your Kindle,” The Verge, 31 January 2020. https://www.theverge.com/2020/1/31/21117217/amazon-kindle-tracking-page-turn-taps-e-reader-privacy-policy-security-whispersync.
Ian Hacking, “The Looping Effects of Human Kinds,” in Causal Cognition: A Multidisciplinary Debate, eds. Dan Sperber, David Premack, and Ann James Premack (Oxford: Clarendon Press, 1995), 353.
Germán Sumbre, Graziano Fiorito, Tamar Flash & Binyamin Hochner, “Motor Control of Flexible Octopus Arms,” Nature, Vol.433, No. 7026 (2005).
Chris Anderson, “The End of Theory: The Data Deluge Makes the Scientific Method Obsolete,” Wired, 23 June 2008. https://www.wired.com/2008/06/pb-theory/.
Heinz von Foerster, “The Curious Behavior of Complex Systems: Lessons from Biology” Special Collections: Oregon Public Speakers, Vol. 125 (Portland: PSU Library Special Collections and University Archives, 1975).
Blake Hallinan & Ted Striphas, “Recommended for You: The Netflix Prize and the Production of Algorithmic Culture,” New Media & Society, Vol. 18, No. 1 (2016), 1-2.
Jonas Andersson Schwarz, "Platform logic: An interdisciplinary approach to the platform‐based economy,” Policy & Internet, Vol. 9, No. 4 (2017): 375.
James C. Scott, Seeing Like a State (London: Yale University Press, 1998).
Friedrich Hayek, Individualism and Economic Order (Chicago: The University of Chicago Press, 1948).
Michael Polanyi, Meaning (Chicago: The University of Chicago Press, 1975).
Matteo Pasquinelli & Vladan Joler. “The Nooscope Manifested: Artificial Intelligence as Instrument of Knowledge Extractivism,” KIM Research Group & Share Lab (2020), 1276.
Jacob Ward, The Loop: How Technology is Creating a World Without Choices and How to Fight Back (New York: Hachette, 2022).
Evgeny Morozov, To Save Everything, Click Here (London: Penguin, 2014), 266.
Nick Bostrom, Superintelligence (Oxford: Oxford University Press, 2014), 10.
Pasquinelli & Joler, “The Nooscope Manifested,” 1272.
Carlos A. Gomez-Uribe & Neil Hunt, “The Netflix Recommender System: Algorithms, Business Value, and Innovation,” ACM Transactions on Management Information Systems, Vol. 6, No. 4 (2015), 3-4.
Tom Vanderbilt, “The Science Behind the Netflix Algorithms That Decide What You'll Watch Next,” Wired, 7 July 2013. https://www.wired.com/2013/08/qq-netflix-algorithm/.
Ibid.
Alexis C. Madrigal, “How Netflix Reverse Engineered Hollywood,” The Atlantic, 2 January 2014. https://www.theatlantic.com/technology/archive/2014/01/how-netflix-reverse-engineered-hollywood/282679/.
Ibid.
Brad Stone, The Everything Store (New York: Random House, 2013), 12.
Roisin Kiberd, The Disconnect (London: Profile Books, 2021), 20.
Sven Birkerts, Gutenberg Elegies (New York: Farrar, Straus and Giroux, 2006), 164.
Henri Lefebvre, Everyday Life in the Modern World (London: Routledge, 1984), 60.
Ted Striphas, “The Abuses of Literacy: Amazon Kindle and the Right to Read,” Communication and Critical/Cultural Studies, Vol. 7, No. 3 (2010), 306.
Rebecca Uliasz, “Seeing Like an Algorithm: Operative Images and Emergent Subjects,” AI & Society, Vol. 36 (2021).
Gregory Bateson, Steps to an Ecology of Mind (New York: Ballantine Books, 1977), 315.
Quoted in Kevin Roose, Futureproof (London: John Murray, 2021), 89-90.
Peter Galison, “The Ontology of the Enemy: Norbert Wiener and the Cybernetic Vision,” Critical Inquiry, Vol. 21, No. 1 (1994), 251.
Brian Ellis: quoted in William A. Bauer & Veljko Dubljević, “AI Assistants and the Paradox of Internal Automaticity,” Neuroethics, Vol. 13, No. 3 (2020), 306.
Amazon, “Leadership Principles,” Amazon Jobs, 2022. https://www.amazon.jobs/en/principles.
Rashmi Sinha & Kirsten Swearingen, “Comparing Recommendations Made by Online Systems and Friends,” DELOS, Vol. 106 (2001), 3.
Frank Kane, Building Recommender Systems with Machine Learning and AI (Sundog Education, 2018), 464.
Katherine Behar, “Personalities Without People,” The Occulture, 21 March 2018. http://www.theocculture.net/personalities-without-people-guest-post-by-katherine-behar/.
Danielle Keats Citron & Frank Pasquale, “The Scored Society: Due Process for Automated Predictions,” Washington Law Review, Vol. 89, No. 1 (2014), 5.
Jodi Kantor, Karen Weise & Grace Ashford, “The Amazon That Customers Don’t See,” The New York Times, 15 June 2021. https://www.nytimes.com/interactive/2021/06/15/us/amazon-workers.html.
Shabana Arora, “Recommendation Engines: How Amazon and Netflix Are Winning the Personalization Battle,” MarTech Advisor, 28 June 2018. https://www.martechadvisor.com/articles/customerexperience-2/recommendation-engines-how-amazon-and-netflix-are-winning-the-personalizationbattle/.
Gediminas Adomavicius, Jesse C. Bockstedt, Shawn P. Curley & Jingjing Zhang, “Effects of Online Recommendations on Consumers’ Willingness to Pay,” Information Systems Research, Vol. 29, No. 1 (2018).
Mark Gillard, “Who's Using Amazon Web Services?” Contino, 28 January 2020. https://www.contino.io/insights/whos-using-aws.
Quoted in Miranda Mowbray, “The Fog Over the Grimpen Mire: Cloud Computing and the Law,” Scripted, Vol. 6 (2009), 137.
Jessica Rapp, “Deep Dive: How to Master Amazon Advertising in the New Normal,” Digiday, 29 July 2020. https://digiday.com/media/deep-dive-how-to-master-amazon-advertising-in-the-new-normal.
Dana Mattioli, “Amazon Retools With Unusual Goal: Get Shoppers to Buy Less Amid Coronavirus Pandemic,” The Wall Street Journal, 16 April 2020. https://www.wsj.com/articles/amazon-retools-with-unusual-goal-get-shoppers-to-buy-less-amid-coronavirus-pandemic-11587034800.
Trevor J. Pinch & Weibe E. Bijker, “The Social Construction of Facts and Artefacts: Or How the Sociology of Science and the Sociology of Technology Might Benefit Each Other,” Social Studies of Science, Vol. 14, No. 3 (1984).
N. Katherine Hayles, “RFID: Human Agency and Meaning in Information-Intensive Environments,” Theory, Culture & Society, Vol. 26, No. 2-3 (2009), 48.